-
Spring Batch 살짝 알아보기-1개발/Spring 2022. 2. 7. 10:30
현재 스프링 배치를 사용하고 있지는 않지만, 3일동안 간략하게 맛보기 스터디를 하면서 공부했던 내용을 정리해 본다.
개요
- 유저 인터랙션이 없는 큰 정보의 고도화되고 자동화된 처리
- 주기적이고 반복적인 큰 데이터리 처리
- 수많은 트랜잭션의 처리
- microservice-based , web-based architecture에서 더 각광받고 있음
사용 시나리오
- 데이터베이스, 파일, 큐 등에서 많은 records를 읽어올 때
- 어떠한 방식으로 데이터를 처리할 때
- 수정된 폼으로 back data를 쓸때
많은 자료를 읽고(Reader), 처리하고(Processor), 저장하는(Writer)에 특화되어 있는 기술이다. 현재 내가 필요한 기술이 아니라 단순히 공부였기 때문에, Retry, Repeat, Parallel Processing 등 다양한 기술을 지원해주지만 기본적인 개념 위주로 공부해보았다.
구조
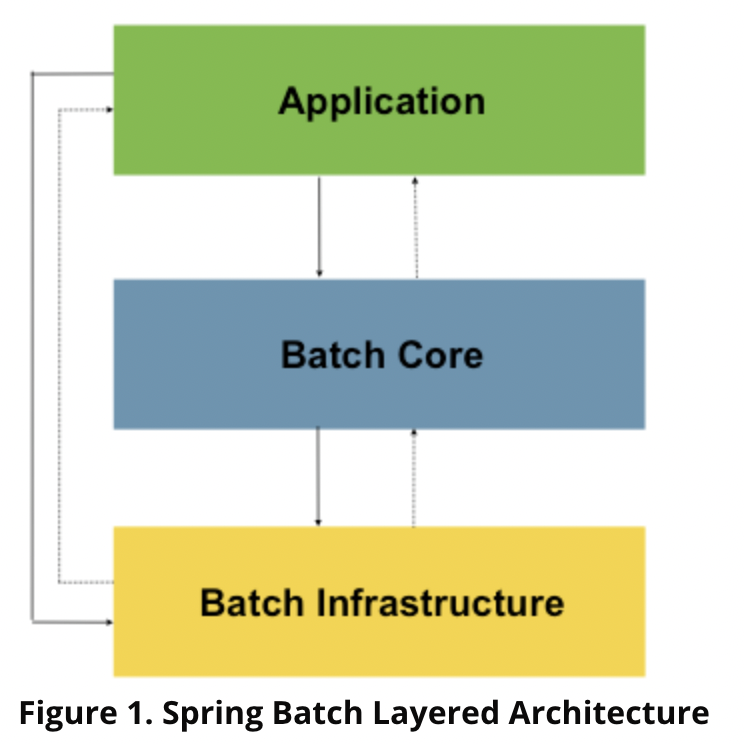
출처: https://docs.spring.io/spring-batch/docs/current/reference/html/spring-batch-intro.html#spring-batch-intro - Application: 모든 배치 jobs, custome code, 개발자들이 작성하는 코드
- Core: 배치 잡을 관리하고 시작할 런타임 클래스들 (JobLauncher, Job, Step)
- Infra: reader, writer, RetryTemplate 같은 서비스들
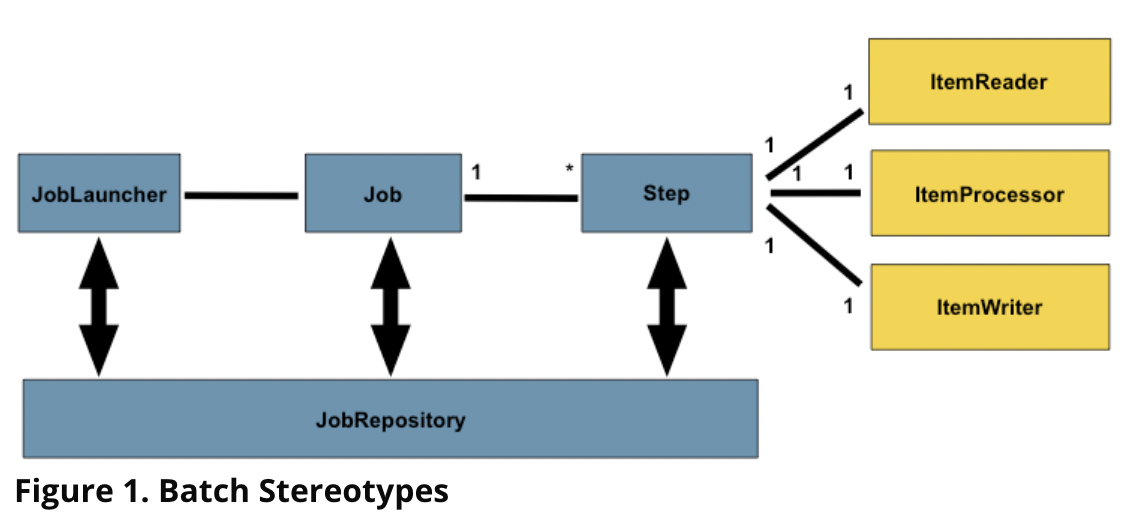
출처: https://docs.spring.io/spring-batch/docs/current/reference/html/domain.html#domainLanguageOfBatch 하나의 Job은 여러개의 Step을 가질 수 있고 각각의 Step은 Reader, Processor, Writer와 1:1로 대응된다.
간단하기 시작해보기
어디서 봤는지 기억이 안나지만 공식문서를 보다보면 간단하게 맛보기 해볼 수 있는 깃허브 저장소가 있다. (깃허브 저장소) 클론받아서 가이드 대로 따라해보았다. csv 파일을 읽어서 소문자로 되어있는 사람의 이름을 대문자로 바꿔 저장해주는 예제 파일이다. 완성된 코드는 해당 깃허브 저장소의 complete 모듈에서 볼 수 있다.
- Configuration 설정 필요
- reader: sample-data.csv 에서 한줄씩 읽어서 Person으로 변환
- processer: PersonItemProcessor (대문자로 변환하도록 정의해 둠)
- writer: DB 반영할 수 있는 내용
- step: reader, processor, writer을 정의한다.
- job: importUserJob, step1
@Configuration @EnableBatchProcessing public class BatchConfiguration { @Autowired public JobBuilderFactory jobBuilderFactory; @Autowired public StepBuilderFactory stepBuilderFactory; @Bean public FlatFileItemReader<Person> reader() { return new FlatFileItemReaderBuilder<Person>() .name("personItemReader") .resource(new ClassPathResource("sample-data.csv")) .delimited() .names(new String[]{"firstName", "lastName"}) .fieldSetMapper(new BeanWrapperFieldSetMapper<Person>() { {setTargetType(Person.class);} }) .build(); } @Bean public PersonItemProcessor processor(){ return new PersonItemProcessor(); // 이 부분은 ItemProcessor를 구현해주어야 한다. } @Bean public JdbcBatchItemWriter<Person> writer(DataSource dataSource) { return new JdbcBatchItemWriterBuilder<Person>() .itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>()) .sql("INSERT INTO people (first_name, last_name) VALUES (:firstName, :lastName)") .dataSource(dataSource) .build(); } @Bean public Job importUserJob(JobCompletionNotificationListener listener, Step step1) { return jobBuilderFactory.get("importUserJob") .incrementer(new RunIdIncrementer()) // DB에 Batch 메타 정보가 저장되는데 RunId 값을 자동으로 증가시켜 주는 설정이다. .listener(listener) // batch 작업 전후로 listener를 등록할 수 있는데 여기서는 batch 완료 후에 DB에서 읽고 로그를 남기도록 하였다. Listener는 JobExecutionListenerSupport를 상속하여 구현하며, @Component 등록을 해준다. .flow(step1) .end() .build(); } @Bean public Step step1(JdbcBatchItemWriter<Person> writer) { return stepBuilderFactory.get("step1") .<Person, Person> chunk(10) // chunk 단위로 Transaction 단위가 관리된다. chunk와 page size는 또 다르므로 page size 설정에 따라 의도한 chuck 사이즈대로 동작하지 않을 수 있다. .reader(reader()) .processor(processor()) .writer(writer) .build(); } }
실행 콘솔 reader/processor/writer를 합쳐놓은 것을 Tasklet이라고 한다. 따라서 Tasklet으로 커스텀하게 하나를 구현할 수도 있고, 위의 예시처럼 reader/processor/writer 를 각각 구현하여 사용할 수도 있다고 한다. Tasklet을 커스텀하게 구현하는 경우는 데이터가 많지 않고 단순한 로직, chunk 단위의 트랜잭션 관리 등이 필요없을 경우에 사용한다고 한다.
정리
말로만 들어보던 batch가 어떤 것이고 어떤 방식으로 구현되는지 간략하게 알아보았다. 일정 시간마다 배치 작업을 돌리기도 하는데 이런 경우 배치와 스케줄러의 역할을 혼돈하기도 한다고 한다. 하지만, 배치의 주된 역할은 대량의 데이터에 대한 처리이고 이것이 일정한 시간에 주기적으로(새벽시간 등) 사용되기 때문에 Quartz 스케줄러 모듈과 같이 사용되기도 한다고 한다.
배치는 reader, processor, writer로 이루어져 있고 Configuration 설정을 통해서 관리된다. 자세히는 모르지만 배치 작업은 어플리케이션이 실행되면 launcher가 실행되어 바로 동작하는 듯 싶다.
참고
'개발 > Spring' 카테고리의 다른 글
Spring Batch 살짝 알아보기-3 (0) 2022.02.13 Spring Batch 살짝 알아보기-2 (2) 2022.02.07